
Unit tests for Large Language Model prompts
Using chains to test your prompts in PlayFetch

If you’d like to join the waitlist for access to PlayFetch you can do so here. If you’d like to get in touch with us directly please send us an email to hello at playfetch dot ai.
PlayFetch makes integrating large language model (LLM) features into your app simple and reliable. Today we’re going to look at how it helps you to iterate on and test prompts in a structured repeatable way. If you haven’t read our first introductory post to PlayFetch, please go ahead and read that first so you know the basics (or watch the video over here on YouTube if you prefer).
Chains in PlayFetch allow you to chain together multiple prompts, along with Javascript code-blocks in between for any processing you might like to do to the raw responses. While you can use this system to make complex endpoints that require multiple models and intermediate logic, you can also use it during your prompt iteration process to score the quality of your outputs and make your iterations a little more deterministic.
It turns out that large language models can be incredibly good at scoring the quality of text across a set of criteria even if they themselves were responsible for the initial generation, although of course you can use different models for generation and scoring in PlayFetch. Determining the quality of an LLM output programatically is hard, but describing the qualities of your desired output in natural language is significantly easier and that’s what we’re taking advantage of here.
Let’s have a look at an example in PlayFetch where I want to make sure some tweets I’m generating meet the criteria I have in mind. The tweets are draft responses to customer tweets for a knitwear brand called Wooly Mitts. Let’s create a simple prompt to write some replies.

Here we’re using GPT 3.5 to generate tweets and they look pretty good. But I can see some things I don’t like (over use of emojis and hashtags for one). Rather than try to fix this by eyeballing the outputs, let’s write another prompt that ranks these generated tweets.

For these kinds of analytical tasks I like to use GPT-4 as it tends to perform better. After writing the prompt I add a single row of test data to make sure I’m getting the output I want. I’ve asked for it to return the scores formatted as JSON which means I can easily manipulate the output to calculate my overall score in Javascript. Let’s create a chain and chain together the writing tweet, the analysis tweet, and a code block and then write a little bit of Javascript to process the analysis object we’ve asked our prompt to produce.

Now that we have this set up we can run our chain for the first time and see what we get.
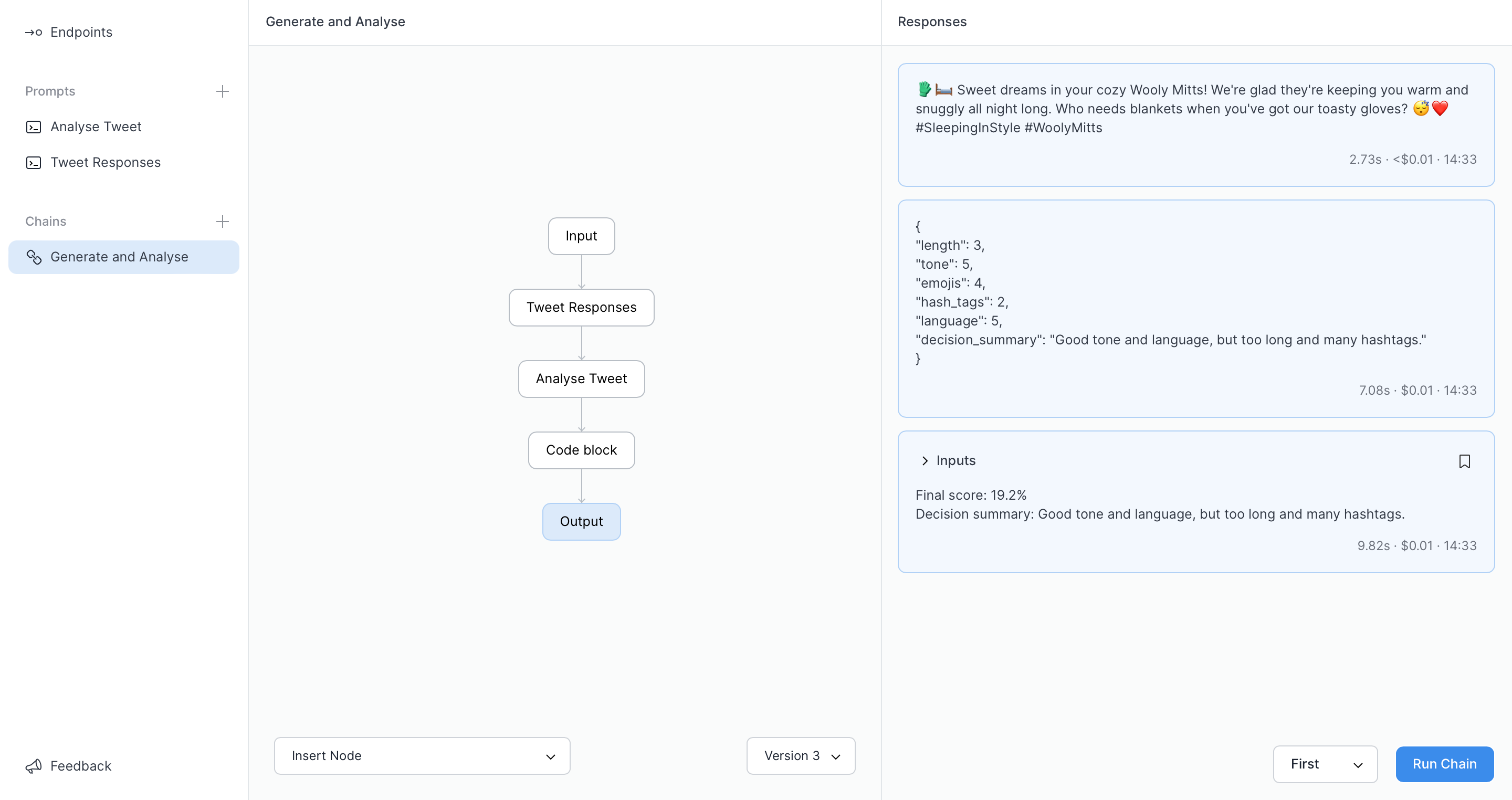
In this output we can see the initially generated tweet, the analysis prompt output, and finally our formatted score. Now, rather than going back to the prompt editor we can edit our generation prompt right here in the chain editor. This means that you can just sit in this interface while you perfect things. Let’s update our generation prompt to see if we can improve the scores we’re getting.

And now we can just click Run Chain again to get our updated outputs. Let’s give it a go.

We did it, a perfect tweet! With a score now generated by the chain each time I run it, I can iterate on my generation prompt (and indeed on my test prompt if I find it passing or failing for the wrong reasons) until I’m happy with the performance. All future changes to my generation prompt can be run through this chain to ensure I don’t regress the score before releasing a new version.
This isn’t totally fool proof (it can take some time to get the hang of writing the analysis prompts) and it may take a while to get used to working in this way, but when you do it makes prompt editing feel much more manageable, particularly when you have multiple people involved in the process.
If you want to try this along with all of the other features of PlayFetch you can join the waitlist here. If you’d like to get in touch with us directly please send us an email to hello at playfetch dot ai.